

Top 5 Model Interpretability Libraries for Python
Top 5 Model Interpretability Libraries for Python
An overview of awesome machine learning model interpretability and explainability libraries

Welcome to the post about the Top 5 Python ML Model Interpretability libraries! You ask yourself how we selected the libraries? Well, we took them from our Best of Machine Learning with Python list. All libraries on this best-of list are automatically ranked by a quality score based on a variety of metrics, such as GitHub stars, code activity, used license and other factors. You can find more details in the best-of-generator repo.
Model interpretability - also known as model explainability - is an important field of machine learning that helps, for instance, with debugging models or detecting issues around biases, or overall increases trust in the results. The overall goal of deploying models to production is to make decisions or build upon them, which can only work when you trust them in the first place!
The intention of this post is to highlight some of the most popular libraries in the field based on our metric and give a crisp overview to make it hopefully easy for you to gain some high-level understanding! If you want to try them out, we can recommend our ml-workspace container to do so, as it comes pre-installed with all but the last of the libraries in the list!
So, that is enough of an introduction, here comes the list of our top 5 interpretability libraries.
1. SHAP
The first library on our list is SHAP and rightly so with an impressive number of 11.4k stars on GitHub and active maintenance with over 200 commits in December alone. SHAP, which is an acronym for SHapley Additive exPlanations, is a model-agnostic explainer library that follows a game theory approach to assign importance values to features. You can find the original paper from 2017 that appeared in NIPS on arxiv.
As the idea behind Shapley Values is already nicely explained by others, for example in this neat book chapter or this well-written blog post, we keep it high-level: it distributes the contribution of a feature related to all combinations of other features. Based on this approach, the library allows to explain individual predictions but also can easily give a global overview.
The theory and math behind it is not so easy to explain, but luckily the library hides all of this from the user. For example, the following image

{kind=link}
can be generated with this code snippet
import shap
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X)
shap.force_plot(
explainer.expected_value,
shap_values[1, :],
X.iloc[1, :],
)where model is the model to be explained and X is the input data. As SHAP is model-agnostic, it works with all kinds of models.
As you can imagine, the computation of the various combinations for many features can be very expensive and so the authors provide a fast C++ implementation for tree models as explained here.
The GitHub page contains nice examples and tutorial notebooks, so it should be quite easy to start with it!
2. Lime
The library Lime, short for Local interpretable model-agnostic explanations, follows second on our list with an impressive number of 8.3k stars, last activity 21 days ago, and some nice tutorials and API definition.
Lime is able to explain tabular data classifiers and text classifiers independent of the actual model. As the authors of SHAP, the authors of Lime came from the University of Washington — well done Washington to have 2 libraries in the top 5 👏 — and you can find their original paper from 2016 also on arxiv.
Lime is a concrete implementation of so-called local surrogate models, which focus on explaining individual predictions of black box models. To do so, Lime generates new data around the data point you want to have an explanation for and trains a linear, interpretable classifier.
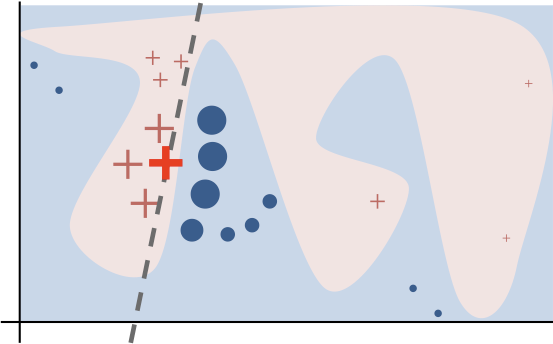
You can then see what features were responsible for the local model’s classification (in this example, it shows which words in the text contributed to the text belonging to the class atheism).
In contrast to SHAP, it does not look like Lime offers an API to conveniently generate a global explanation or at least we missed this. However, by generating multiple explanations for different examples, you could gain an understanding of the original model’s behavior.
3. ELI5
The Python library ELI5 provides a unified API for debugging and explaining machine learning classifiers. The term ELI5 can be found in the urban dictionary and is slang for Explain Like I am 5. For black-box models it offers an implementation of the Lime algorithm for texts. Besides that, it offers support for scikit-learn, XGBoost, LightGBM, CatBoost, lightning, sklearn-crfsuite, and Keras. Check out their documentation for examples and an API reference.
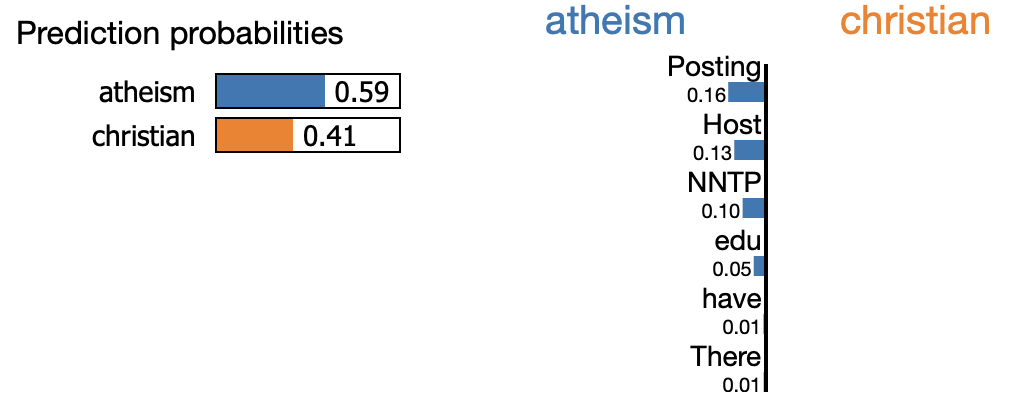
The following image shows how an explanation by ELI5 looks like for a text classification, where it shows which words contribute how much to a specific class.

It is generated by this code
import eli5
eli5.show_weights(
clf, vec=vec, top=10, target_names=target_names
)where clf is, for example, an sklearn LogisticRegressionCV, vec is a vectorizer, for example an sklearn CountVectorizerthat transform texts into a token count matrix, top is the number of features to show per class in the image, and target_names tells eli5 the actual labels of the classification based on the input data.
4. pyLDAvis
As the name already suggests, pyLDAvis focuses on LDA topic models. It can be used to interactively visualize them within Jupyter Notebooks. The documentation contains example videos and also an overview notebook, though compared with the other libraries the API could have been documented a little bit better. The original paper from 2014 explains the methodology and can be found here.
The documentation states that this lib is agnostic to how the model was trained, as you only need the topic-term distribution, document-topic distributions, and basic corpus information. For sklearn, gensim, and graphlab it even has convenient methods. For example, the following code utilizing the gensim helper function
import pyLDAvis.gensim
pyLDAvis.gensim.prepare(lda, corpus, dictionary)would output an interactive graphic which is displayed in the following image. The params lda is a gensim lda model, corpus is a gensim matrix market corpus, and dictionary is a gensim dictionary (see their docs for the complete example. That's it!
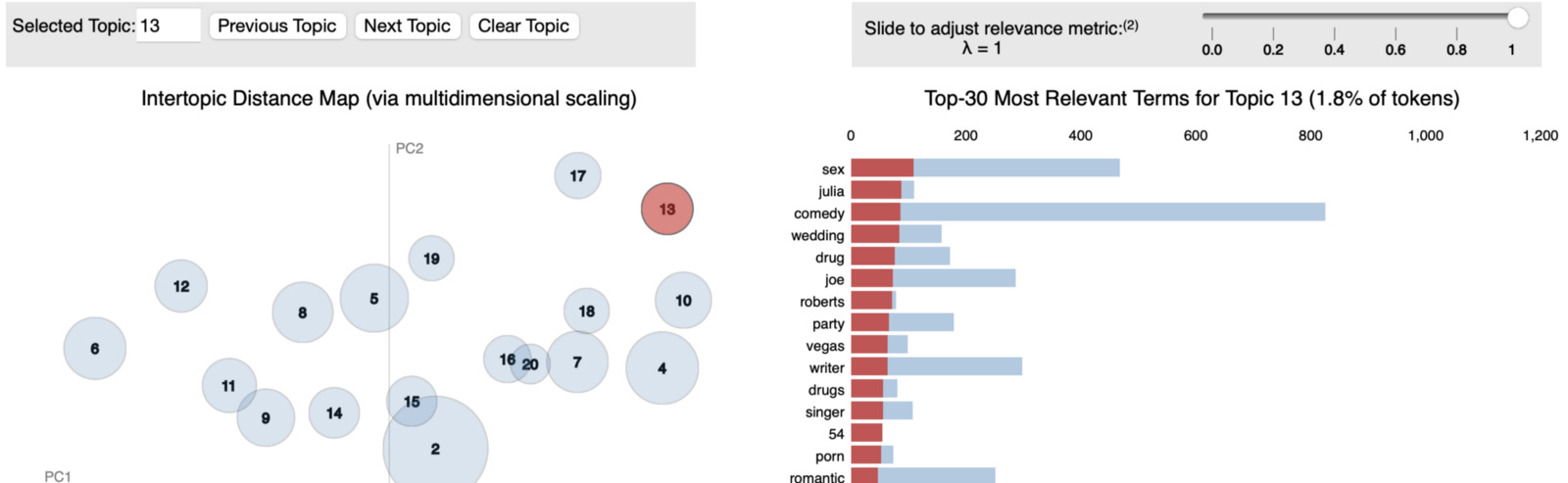
In the interactive visualization, you can click on the different topics, see which words belong to them, change the weighting parameter and such things!
5. InterpretML
InterpretML is in Alpha Release but already made it into the top 5 and is under active development; even one of our Pull Requests on GitHub we created during writing this post was merged within 7 hours 🥳! It is a library from Microsoft and has two functionalities: first, training glassbox models that are interpretable and, second, explaining blackbox models. Their paper can be found here. In their Supported Techniques section they mention the techniques the library brings with it, for example Decision Tree and SHAP Kernel Explainer as a glassbox model or blackbox explainer, respectively. As you can see, in the interpretability library world, the same techniques and libraries show up and are cross-referenced or used from each other.
The library is supposed to work for shedding light on individual predictions as well as making the global behavior understandable, which is also reflected in the API. With following lines of code, you can train one of their glassbox models and get some visualization for local and global interpretability
from interpret.glassbox import ExplainableBoostingClassifier
from interpret import show
# train
ebm = ExplainableBoostingClassifier()
ebm.fit(X_train, y_train)
# global
ebm_global = ebm.explain_global()
show(ebm_global)
# local
ebm_local = ebm.explain_local(X_test, y_test)
show(ebm_local)You can even pass an array of explanations to their show function to get a comparison visualization.
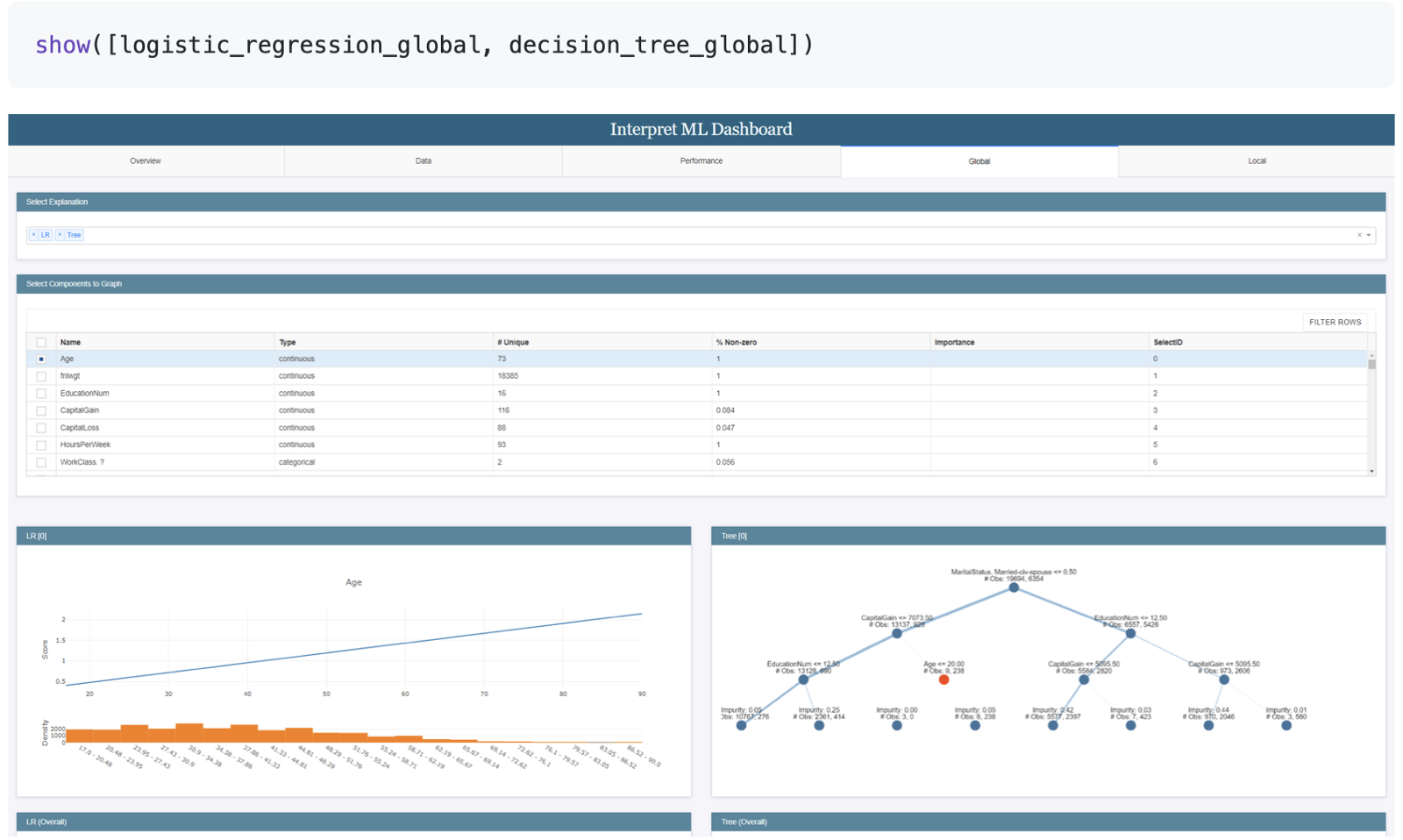
The documentation links some more example notebooks for the other techniques, too, as well as tutorial videos or blog posts which are interesting to check out for those of you who want to go more into breadth or depth!
If you liked this overview, have a look at the other Python Machine Learning Libraries we ranked in our best-of list.
And, of course, we are very happy about all kinds of feedback! Leave a comment or get in touch with us via team@mltooling.org or via Twitter @mltooling.
With ❤️ from Berlin!